


Entropy in the Opening
Using information theory to quantify the surprise value of chess openings

In 1950 Claude Shannon published the first paper on programming a computer to play chess. It was entirely theoretical: he didn’t yet describe how the program would actually be implemented. Yet in broad strokes, most computer programs up to AlphaZero in 2017 followed the outline Shannon laid out in the paper. As prescient as that was, it was far from Shannon’s most consequential contribution to science.

Shannon developed what became known as information theory, a branch of science that underpins computers, the internet, and quantum mechanics. At the core of information theory is a measure of information called entropy. According to one story, the name arose from a conversation with John von Neumann, who advised him to use “entropy” for two reasons: first, a similar concept existed in physics by that name; second, no one knew what it meant, so he would always have an advantage in an argument. At any rate, the name stuck.
Von Neumann developed game theory, the branch of math that is most relevant to how advanced poker players now think about the game, but entropy is more closely related to another concept from poker: expected value. The expected value of a situation is what you would expect to get, on average, if you played it out many times. In poker, since you can’t control what cards come out after you’re all-in, advanced players focus on expected value. While anyone can get lucky in the short run, in the long run, the winner will be the one who maximizes their expected value.

The equation for expected value is the chance of an event happening, times the win or loss of that event, added up for all possible events. Shannon’s entropy is also a form of expected value, but rather than expected money won or lost, it’s expected information gained. The question is, what unit could represent information?
Shannon’s insight was that information is closely tied to surprise. As I’m writing this, we’re one game into the NBA finals, with the Boston Celtics leading the Golden State Warriors by one game. Imagine you’re thinking about placing a bet on game two. As far as anyone knows, Celtics star Jayson Tatum is healthy going into game two, but say there’s a 1-in-1000 chance Tatum sustains a freak injury that prevents him from playing in game two. Which would be more valuable to know before you place your bet - Tatum is healthy, or he’s injured?
Finding out that he’s healthy doesn’t tell you much beyond what you already knew. There was already a 999/1000 of that, so ruling out the 1/1000 chance that he could be injured probably won’t change your bet. But if you find out he’s injured it’s a whole different ball game. Now you have a really important piece of information that up until that moment you had considered incredibly unlikely. This will probably change your bet a lot. This is the key idea: if an event is less likely, it’s more surprising; and if it’s more surprising, it conveys more information.
To express that mathematically Shannon started by taking the inverse of probability. The inverse of 999/1000 is a hair over 1, while the inverse of 1/1000 is 1000. The unlikely event receives a far higher score. Then he put it into a logarithmic scale. (Logarithms are the opposite of exponents in the same way that division is the opposite of multiplication.) Finally he did a little rearranging. It turns out that log(1/p) is the same thing as -log(p). And adding up a bunch of negatives is the same thing as adding them all up and making the whole thing negative, so he moved the minus sign outside of the sum. All this rejiggering kind of obscures the core idea of the formula, but at the end of the day it’s just a different kind of expected value.
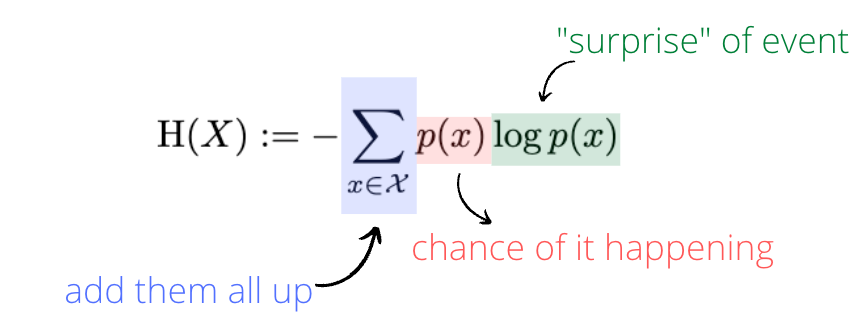
There’s a phase of a chess game where surprise is extremely relevant: the opening. I wondered what would happen if I calculated the entropy of the openings from the games from of the current Norway Chess tournament. To estimate the probability distribution of the moves, I used the Lichess masters database. I assumed the probability of each move was the frequency with which it had been played in previous master games. This isn’t quite right - moves that have never been played in practice will be assigned zero probability, but every legal move should have some probability, no matter how small - but it’s not a bad starting point. I calculated the entropy based on this distribution, then looked at the “surprise” value of the move actually played. Here are the results for the game between Carlsen and Radjabov.

Remember, entropy is the “expected surprise.” High entropy positions are forks in the road, positions where you’re likely to get a lot of information about which direction the game is headed. In chess these positions are called tabiya. For example, the highest entropy position in this game between Carlsen and Radjabov is this one.
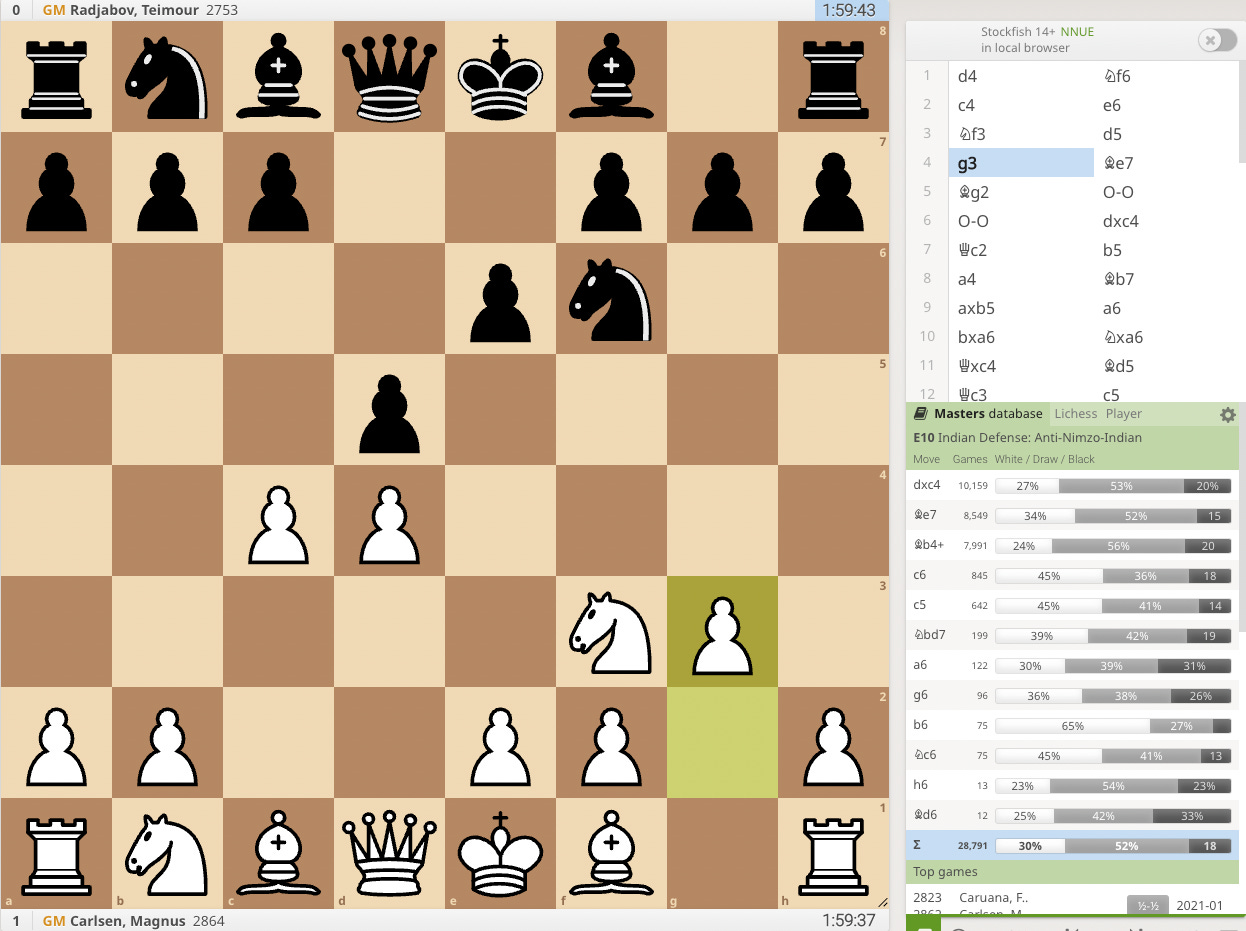
This is a position where Black has three choices - dxc4, Be7, or Bb4+ - that are close to equally popular. It turns out that entropy is highest when the probabilities are split equally between the possible outcomes. In our Jayson Tatum scenario from earlier, the entropy would be very low because the possibilities are so disparate. The highest entropy distribution for two outcomes would be a coinflip, a 50-50 shot.

In contrast, the surprise value is more straightforward. It’s basically just a measure of how unusual the move is. In this position, previously b4 had usually been played, 430 out of 462 games, so the entropy - the expected surprise - was quite low. (Actually the Lichess database is a little out of date here and Bb7 has been more popular recently, but let’s not worry too much about that.) But Radjabov played Bb7, leading to a very high surprise score. He ended up losing the game, but his problems didn’t start until later in the game.
For those designing opening repertoires, entropy offers another way of thinking about the tradeoffs of different lines. A low-entropy repertoire offers fewer options for the opponent, making it easier to learn and perhaps more effective competitively. Although somehow I doubt Shannon would have been interested in such a strategy. He was always in search of the next surprise.
Very novel. Thanks Nate!
Very interesting and thought provoking Nate. Thanks.